알고리즘 설계(Algorithm Design)와 데이터 처리 최적화 분야에서 정렬(Sorting)은 가장 기초적이면서도 중요한 과정입니다. 대부분의 정렬 알고리즘은 두 요소의 크기를 비교하는 비교 정렬(Comparison Sorting) 방식을 채택하며, 이는 이론적으로 $O(N \log N)$의 시간 복잡도라는 한계를 가집니다. 그러나 카운팅 정렬(Counting Sort)은 데이터를 직접 비교하지 않고 데이터의 개수를 세는 방식을 통해 $O(N)$이라는 파격적인 시간 성능을 구현합니다. 이는 특정 조건 하에서 데이터 정렬의 효율성을 극대화할 수 있는 비비교 정렬(Non-comparison Sorting)의 정수로 간주됩니다. 현대의 대규모 로그 분석이나 특정한 범위를 가진 데이터 집합을 처리할 때 카운팅 정렬은 시스템의 응답 속도를 혁신적으로 개선하는 핵심 기술로 활용되고 있습니다.
1. 카운팅 정렬의 핵심 기술 원리와 작동 방식
카운팅 정렬(Counting Sort)의 근본적인 작동 원리는 데이터의 값 자체를 배열의 인덱스(Index)로 사용하여 해당 값이 등장하는 빈도수(Frequency)를 기록하는 데 있습니다. 마치 과일 가게 주인이 사과를 크기별로 분류된 상자에 담아두었다가 나중에 작은 상자부터 순서대로 꺼내는 것과 같이, 데이터가 위치해야 할 자리를 미리 확보해 두는 전략을 사용합니다. 이 과정에서 각 데이터 간의 크기 비교가 발생하지 않으므로, 정렬에 소요되는 시간은 데이터의 개수($N$)와 데이터의 최대값 범위($K$)에 비례하는 $O(N + K)$를 달성하게 됩니다. 이는 퀵 정렬(Quick Sort)이나 병합 정렬(Merge Sort)보다 수치적으로 우월한 성능을 보여줍니다.
이 알고리즘은 단순히 순서대로 출력하는 것을 넘어, 안정 정렬(Stable Sort)의 특성을 유지하기 위해 누적 합(Prefix Sum) 개념을 도입합니다. 빈도수 배열을 생성한 뒤, 각 인덱스의 값을 이전 인덱스의 값과 더해 나가는 과정을 거치면 해당 숫자가 결과 배열에서 끝날 수 있는 마지막 위치를 알 수 있게 됩니다. 이러한 구조적 설계는 동일한 값을 가진 데이터들의 상대적인 순서가 정렬 후에도 바뀌지 않도록 보장하며, 이는 객체 지향 프로그래밍(Object-Oriented Programming) 환경에서 다중 조건 정렬을 수행할 때 매우 중요한 기술적 이점으로 작용합니다. 따라서 카운팅 정렬은 단순한 숫자 정렬을 넘어 복합적인 데이터 구조의 정렬을 위한 하부 알고리즘으로도 널리 사용됩니다.
또한, 카운팅 정렬은 데이터의 분포가 조밀하고 범위가 제한적일 때 최상의 효율을 발휘합니다. 비교 연산에 소요되는 CPU 사이클을 절약할 수 있기 때문에 저사양 하드웨어 환경이나 실시간 시스템(Real-time System)에서 정렬 병목 현상을 해결하는 데 탁월한 선택이 됩니다. 다만, 정렬을 위해 추가적인 카운트 배열(Count Array)을 생성해야 하므로 메모리 사용량과 시간 효율성 사이의 균형을 맞추는 것이 설계의 핵심입니다. 이러한 이론적 배경은 개발자가 문제의 특성에 맞춰 최적의 정렬 전략을 선택할 수 있는 기준을 제공하며, 알고리즘의 시간적 한계를 극복하는 혁신적인 사고의 틀을 제시합니다.
2. 효율적인 구현 방법 및 단계별 가이드
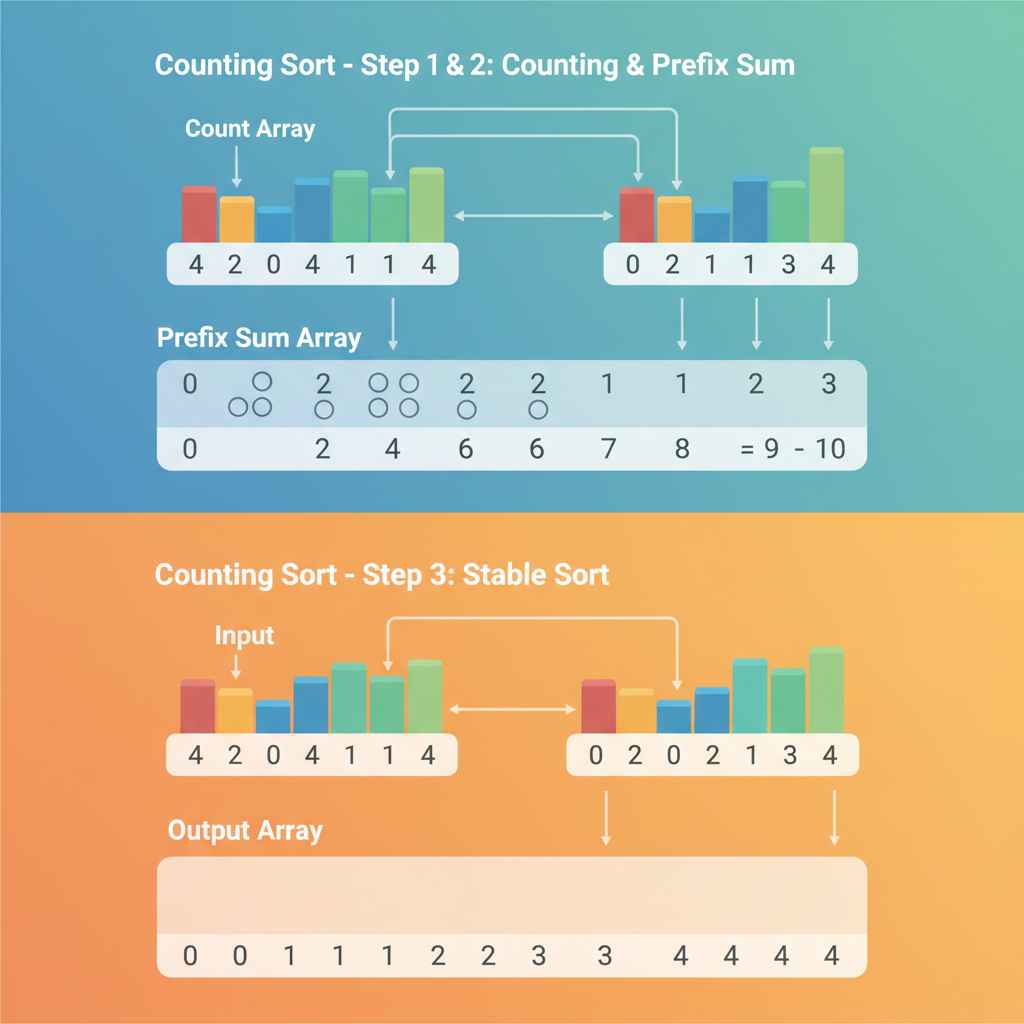
카운팅 정렬(Counting Sort)을 성공적으로 구현하기 위해서는 먼저 입력 데이터의 최대값($K$)을 정확히 파악해야 합니다. 구현의 첫 번째 단계는 크기가 $K+1$인 카운트 배열을 생성하고 모든 요소를 0으로 초기화하는 것입니다. 이후 입력 배열을 순회하며 각 데이터 값을 인덱스로 사용하여 해당 위치의 카운트 값을 1씩 증가시킵니다. 마치 투표용지를 개표하면서 후보자별 득표수를 집계표에 기록하는 과정과 같이 데이터의 분포를 수치화하는 과정이 수행됩니다. 이 단계에서 발생하는 시간 복잡도는 입력 배열의 길이인 $N$에 비례하게 됩니다.
두 번째 단계는 안정성(Stability) 확보를 위한 누적 합 계산입니다. 카운트 배열의 첫 번째 요소부터 마지막 요소까지 순차적으로 누적 합을 구함으로써, 각 데이터가 결과 배열에 들어갈 위치(Index)를 확정합니다. 예를 들어 '3'이라는 숫자의 누적 합이 5라면, 이는 정렬된 배열에서 '3'이 최대 5번째 자리에 위치할 수 있음을 의미합니다. 이 과정은 카운팅 정렬을 안정 정렬로 만들어주는 결정적인 단계이며, 데이터의 삽입 위치를 예측 가능하게 만들어 줍니다. 이어서 결과 배열(Output Array)을 생성하고, 입력 배열의 뒤쪽 요소부터 하나씩 꺼내어 카운트 배열을 참조하며 결과 배열의 적절한 위치에 배치합니다.
마지막으로, 입력 배열을 역순으로 탐색하며 데이터를 배치하는 것이 중요합니다. 이는 동일한 값을 가진 요소들 중 뒤에 있던 요소가 결과 배열에서도 뒤에 위치하도록 보장하여 안정성을 완성하기 위함입니다. 데이터를 하나씩 배치할 때마다 카운트 배열의 해당 값을 1씩 감소시켜 다음 동일 값의 위치를 갱신합니다. 이러한 구현 단계는 정교한 인덱스 제어가 요구되지만, 일단 완료되면 비교 정렬이 도달할 수 없는 압도적인 속도를 체감할 수 있습니다. 각 단계의 메모리 참조 효율성(Memory Reference Efficiency)을 고려하여 코드를 작성한다면, 대규모 정수형 데이터 셋을 처리할 때 최상의 성능을 이끌어낼 수 있습니다.
3. 카운팅 정렬 적용 시 주의사항과 한계점 분석
카운팅 정렬(Counting Sort)은 성능적으로 우수하지만, 사용 환경에 따른 명확한 한계점이 존재하므로 적용 전 신중한 판단이 필요합니다. 가장 큰 제약 사항은 공간 복잡도(Space Complexity)입니다. 이 알고리즘은 데이터의 최댓값만큼의 배열 공간을 필요로 하므로, 데이터의 개수는 적지만 그 값의 범위가 매우 넓은 경우 심각한 메모리 낭비(Memory Waste)를 초래할 수 있습니다. 모기 한 마리를 잡기 위해 거대한 공장 전체를 가동하는 것과 같이, 숫자 몇 개를 정렬하기 위해 수 기가바이트(GB)의 메모리를 할당하는 비효율적인 상황이 발생할 수 있으므로 주의가 필요합니다.
두 번째 한계는 정수 기반 데이터의 정렬에 특화되어 있다는 점입니다. 데이터의 값을 배열의 인덱스로 사용하기 때문에, 정수가 아닌 실수(Float)나 문자열(String) 데이터를 직접적으로 정렬하기에는 부적합합니다. 비록 정수 매핑(Mapping) 기술을 통해 우회할 수는 있으나, 이 경우 구현의 복잡도가 증가하고 카운팅 정렬 고유의 단순함과 효율성이 퇴색될 수 있습니다. 따라서 부동 소수점 정렬이 필요한 경우에는 버킷 정렬(Bucket Sort)이나 기수 정렬(Radix Sort)과 같은 대안을 고려하는 것이 기술적으로 더 합리적인 선택이 될 수 있습니다.
또한, 음수(Negative Number) 처리 문제도 고려해야 할 요소입니다. 일반적인 배열 인덱스는 음수를 허용하지 않으므로, 데이터에 음수가 포함되어 있다면 최소값만큼 모든 데이터에 오프셋(Offset)을 더해 양수로 변환한 뒤 정렬을 수행하고 다시 원래대로 돌리는 추가 연산이 필요합니다. 이러한 예외 처리 과정에서 조건문과 연산이 추가되면 순수한 $O(N+K)$의 효율이 다소 감소할 수 있습니다. 결과적으로 카운팅 정렬은 데이터의 특성이 정해진 범위 내의 정수일 때 가장 빛을 발하는 '특수 목적용 알고리즘'에 가까우며, 개발자는 데이터의 분포 밀도(Density)를 사전에 분석하여 이 기법의 도입 타당성을 검증해야 합니다.
4. 카운팅 정렬의 실무 응용 및 확장 가능성
카운팅 정렬(Counting Sort)은 단독으로 사용될 때보다 다른 알고리즘의 구성 요소로서 결합될 때 그 가치가 더욱 증폭됩니다. 가장 대표적인 확장 사례는 기수 정렬(Radix Sort)입니다. 기수 정렬은 큰 범위의 숫자를 자릿수별로 나누어 정렬하는 방식인데, 각 자릿수의 범위는 보통 0에서 9 사이로 매우 좁기 때문에 자릿수 정렬 단계에서 카운팅 정렬을 사용합니다. 이를 통해 카운팅 정렬의 단점인 메모리 소모를 해결하면서도 전체 정렬 속도를 선형 시간에 가깝게 유지하는 하이브리드 전략을 구현할 수 있습니다.
또한, 문자열 처리 알고리즘인 접미사 배열(Suffix Array) 구축 과정에서도 카운팅 정렬은 핵심적인 역할을 수행합니다. 수만 자 이상의 문자열에서 접미사들을 정렬할 때 반복적으로 발생하는 비교 연산을 제거하기 위해 카운팅 정렬을 도입함으로써, 전체 알고리즘의 복잡도를 획기적으로 낮출 수 있습니다. 이는 정보 검색 엔진(Information Retrieval Engine)의 인덱싱 속도를 높이는 데 직접적인 기여를 합니다. 실무적으로는 이러한 고급 자료구조의 성능 최적화를 위해 카운팅 정렬의 원리를 응용하는 사례가 빈번하며, 이는 중급 이상의 개발자에게 필수적인 응용 능력으로 평가받습니다.
데이터 엔지니어링(Data Engineering) 분야에서는 카테고리성 데이터(Categorical Data)의 빈도수 집계와 정렬을 동시에 수행해야 할 때 이 기법이 활용됩니다. 예를 들어 수억 건의 사용자 평점(1~5점)을 정렬하는 작업은 비교 정렬을 쓸 이유가 전혀 없는 최적의 사례입니다. 5개의 카운트 변수만으로 정렬을 끝낼 수 있기 때문입니다. 이처럼 카운팅 정렬은 단순한 교육용 알고리즘을 넘어 실무 현장에서 병목 현상을 타파하는 강력한 무기로 작동합니다. 기술의 원리를 명확히 이해하고 적재적소에 배치하는 설계 역량은 소프트웨어의 완성도를 결정짓는 차별화된 경쟁력이 됩니다.
5. 카운팅 정렬 실무 경험 및 개발자로서의 소회
몇 달 전 새벽까지 버그를 수정하던 중에 겪었던 일인데, 사용자들의 랭킹 포인트 데이터를 정렬하는 기능을 개선하고 있었거든요. 데이터 개수가 꽤 많길래 무조건 빠른 게 최고라는 생각에 예전에 배웠던 카운팅 정렬을 냅다 적용했죠. 근데 테스트 서버를 돌리자마자 메모리 부족(OOM) 에러가 뜨면서 서버가 뻗어버리더라고요. 알고 보니 사용자의 최대 포인트가 수억 대가 넘어가는 케이스가 있었는데, 제가 그 범위를 체크 안 하고 무턱대고 거대한 배열을 선언해 버렸던 거네요.
당시에는 왜 터지는지 몰라 식은땀을 줄줄 흘리며 답답해했었는데, 동료 개발자가 넌지시 "K 값이 너무 큰 거 아니에요?"라고 힌트를 줘서 금방 깨달았죠. 숫자 몇 개 정렬하려고 기가바이트 단위의 공간을 쓰려 했으니 당연한 결과였더라고요. 결국 데이터의 범위가 넓은 경우에는 카운팅 정렬 대신 퀵 정렬로 회귀해서 문제를 해결했답니다. 그날 이후로는 아무리 속도가 탐나도 데이터의 분포와 범위를 먼저 확인하는 습관이 생겼어요. 여러분은 저처럼 무작정 빠르다는 말에 혹해서 메모리 낭비하지 마시고, 상황에 맞는 정렬 도구를 고르는 안목을 기르셨으면 좋겠어요!
- 카운팅 정렬(Counting Sort)은 비교 없이 빈도수를 활용해 $O(N+K)$의 속도를 내는 알고리즘입니다.
- 데이터의 범위(K)가 데이터 개수(N)에 비해 지나치게 크면 메모리 효율이 급격히 떨어집니다.
- 안정 정렬을 위해 누적 합(Prefix Sum)을 사용하여 데이터의 최종 위치를 결정하는 것이 핵심 구현 포인트입니다.