
티스토리 뷰
목차
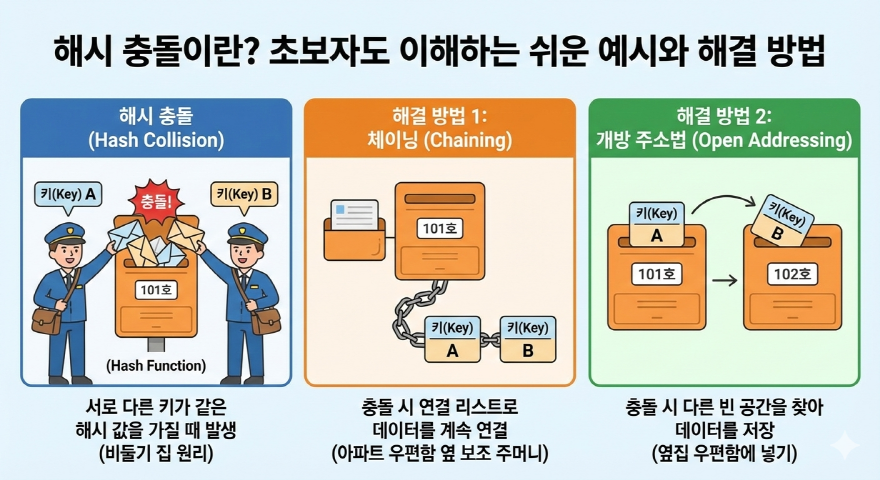
이전 글에서 우리는 해시 테이블(Hash Table)이 해시 함수를 통해 어떻게 O(1)이라는 마법 같은 검색 속도를 달성하는지 배웠습니다. 모든 것이 완벽해 보이는 이 자료구조에도 현업 개발자들을 골치 아프게 만드는 치명적인 아킬레스건이 하나 존재합니다. 바로 '해시 충돌(Hash Collision)'입니다. "어? 내가 저장하려는 자리에 이미 다른 데이터가 들어앉아 있네?"라는 당혹스러운 상황을 마주하게 되는 것인데요. 한정된 메모리 공간이라는 현실적인 물리적 제약 속에서, 이 충돌은 알고리즘의 결함이 아니라 피할 수 없는 자연의 섭리와도 같습니다. 오늘은 면접관들이 가장 사랑하는 질문 중 하나인 해시 충돌의 개념과, 이를 우아하게 극복해 내는 선배 개발자들의 2가지 핵심 해결 전략을 완벽하게 정리해 드리겠습니다.
1. 해시 충돌(Hash Collision)은 왜 발생할까?
해시 충돌을 가장 쉽게 이해하는 방법은 수학의 '비둘기집 원리(Pigeonhole Principle)'를 떠올리는 것입니다. 비둘기집(저장 공간)은 10개밖에 없는데, 들어갈 비둘기(데이터)가 11마리라면? 최소한 1개의 집에는 비둘기가 2마리 이상 들어가야만 합니다. 컴퓨터의 메모리(RAM) 용량은 무한하지 않기 때문에, 해시 테이블의 배열 크기 역시 유한하게 설정될 수밖에 없습니다.
1-1. 우연의 일치가 빚어낸 참사
해시 함수는 임의의 길이의 데이터를 고정된 길이의 숫자로 쪼개고 변형하는 역할을 합니다. 아무리 성능이 뛰어난 해시 함수(예: SHA-256)를 설계하더라도, 서로 완전히 다른 키(Key)를 입력했을 때 우연히 똑같은 해시값(Index 숫자)이 튀어나올 확률은 0%가 될 수 없습니다.
예를 들어 여러분의 연락처 해시 테이블에서 `hash("김철수")`가 연산을 거쳐 `7`번 인덱스를 배정받아 번호를 얌전히 저장했습니다. 그런데 며칠 뒤 `hash("이영희")`를 입력했더니, 공교롭게도 이 문자열의 해시 연산 결과 역시 `7`번이 나와버렸습니다. 컴퓨터가 7번 방으로 데이터를 저장하러 갔더니 이미 '김철수'의 데이터가 자리를 차지하고 있습니다. 이때 덮어쓰기를 해버리면 철수의 데이터는 영영 날아가 버립니다. 이것이 바로 '해시 충돌'이며, 이 교통정리를 제대로 해주지 않으면 시스템은 심각한 데이터 유실 에러를 뿜어내게 됩니다.
2. 해결책 1: 체이닝 (Chaining) - "사이좋게 같이 쓰자!"
해시 충돌을 해결하는 가장 전통적이고 대중적인 접근법은 체이닝(Chaining)입니다. 단어 뜻 그대로 데이터를 쇠사슬(Chain)처럼 줄줄이 엮어버리는 방식입니다. 자바(Java)의 HashMap이 내부적으로 이 방식을 채택하여 사용하고 있습니다.
2-1. 연결 리스트(Linked List)의 활용
체이닝 기법을 적용하면, 해시 테이블의 각 방(Bucket)은 단순한 데이터가 아니라 '연결 리스트'의 머리(Head) 주소를 가지게 됩니다. 앞선 예시에서 "이영희"의 데이터가 7번 방으로 갔을 때, "김철수"의 데이터를 밀어내는 대신 "김철수" 데이터의 꼬리 부분에 포인터를 연결하여 "이영희" 데이터를 매달아 둡니다. 만약 또 7번 방에 배정받는 데이터가 오면 그 뒤에 계속해서 기차처럼 이어 붙입니다.
- 장점: 구현 구조가 직관적이고, 해시 테이블의 기본 배열 크기를 무리하게 확장하지 않아도 무한히 데이터를 받아들일 수 있습니다.
- 단점: 특정 방에만 데이터가 몰리는 '쏠림 현상'이 발생하면, 해당 방에서 데이터를 검색할 때 연결 리스트를 순차적으로 다 뒤져야 하므로(O(n)), 해시 테이블의 존재 이유인 O(1)의 속도를 잃어버리게 됩니다.
3. 해결책 2: 개방 주소법 (Open Addressing) - "다른 빈방 찾아볼게!"
개방 주소법은 체이닝처럼 연결 리스트라는 외부 포인터 메모리를 추가로 쓰지 않고, 오직 주어진 해시 테이블 배열 내부의 빈 공간만을 활용하여 문제를 해결하려는 방식입니다.
3-1. 선형 탐사 (Linear Probing)
가장 대표적인 개방 주소법입니다. 7번 방에 갔더니 이미 자리가 찼다면, 바로 옆방인 8번 방을 똑똑 두드려 봅니다. 8번 방이 비어있다면 거기에 "이영희" 데이터를 쓱 집어넣습니다. 만약 8번도 차 있다면 9번, 10번... 빈방이 나올 때까지 무조건 한 칸씩 옆으로 이동하며 탐색합니다.
- 장점: 외부 메모리를 끌어다 쓰지 않으므로 CPU 캐시 메모리 활용도(Cache Locality)가 매우 높아 성능이 좋습니다.
- 단점: 데이터들이 한 구역에 옹기종기 모여버리는 '클러스터링(Clustering, 군집화)' 현상이 발생하기 쉽습니다. 덩어리가 커질수록 빈방을 찾기 위해 점프해야 하는 횟수가 기하급수적으로 늘어나 검색 속도가 끔찍하게 느려집니다.
4. 근본적인 예방: 로드 팩터(Load Factor) 관리
체이닝이나 개방 주소법 모두 충돌을 '사후 수습'하는 방법입니다. 애초에 충돌 확률을 낮추려면 어떻게 해야 할까요? 방의 개수 자체를 넉넉하게 늘려주면 됩니다. 해시 테이블에는 전체 방의 개수 대비 현재 데이터가 들어찬 비율을 나타내는 '로드 팩터(Load Factor)'라는 지표가 있습니다. 일반적으로 이 비율이 70%~75%를 넘어가게 되면, 컴퓨터는 충돌이 잦아질 것을 대비하여 기존 배열보다 2배 더 큰 새로운 배열을 만들고, 모든 데이터를 새로운 배열에 재배치하는 '리사이징(Resizing)' 작업을 백그라운드에서 수행합니다. 이를 통해 최적의 퍼포먼스를 유지하는 것입니다.
1. 해시 충돌은 한정된 메모리 크기 때문에, 서로 다른 Key가 해시 함수를 거쳐 동일한 Index 번호를 배정받을 때 발생하는 필연적 현상입니다.
2. 체이닝(Chaining) 기법은 충돌이 난 방에 연결 리스트를 매달아 데이터를 기차처럼 이어 붙여 충돌을 해결합니다.
3. 개방 주소법(Open Addressing)은 충돌 발생 시 규칙(예: 한 칸 옆으로)에 따라 다른 빈방을 찾아 데이터를 저장하여 메모리 낭비를 줄입니다.